Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes
September 21, 2023
Posted by Cheng-Yu Hsieh, Student Researcher, and Chen-Yu Lee, Research Scientist, Cloud AI Team
Quick links

Large language models (LLMs) have enabled a new data-efficient learning paradigm wherein they can be used to solve unseen new tasks via zero-shot or few-shot prompting. However, LLMs are challenging to deploy for real-world applications due to their sheer size. For instance, serving a single 175 billion LLM requires at least 350GB of GPU memory using specialized infrastructure, not to mention that today's state-of-the-art LLMs are composed of over 500 billion parameters. Such computational requirements are inaccessible for many research teams, especially for applications that require low latency performance.
To circumvent these deployment challenges, practitioners often choose to deploy smaller specialized models instead. These smaller models are trained using one of two common paradigms: fine-tuning or distillation. Fine-tuning updates a pre-trained smaller model (e.g., BERT or T5) using downstream manually-annotated data. Distillation trains the same smaller models with labels generated by a larger LLM. Unfortunately, to achieve comparable performance to LLMs, fine-tuning methods require human-generated labels, which are expensive and tedious to obtain, while distillation requires large amounts of unlabeled data, which can also be hard to collect.
In “Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes”, presented at ACL2023, we set out to tackle this trade-off between model size and training data collection cost. We introduce distilling step-by-step, a new simple mechanism that allows us to train smaller task-specific models with much less training data than required by standard fine-tuning or distillation approaches that outperform few-shot prompted LLMs’ performance. We demonstrate that the distilling step-by-step mechanism enables a 770M parameter T5 model to outperform the few-shot prompted 540B PaLM model using only 80% of examples in a benchmark dataset, which demonstrates a more than 700x model size reduction with much less training data required by standard approaches.
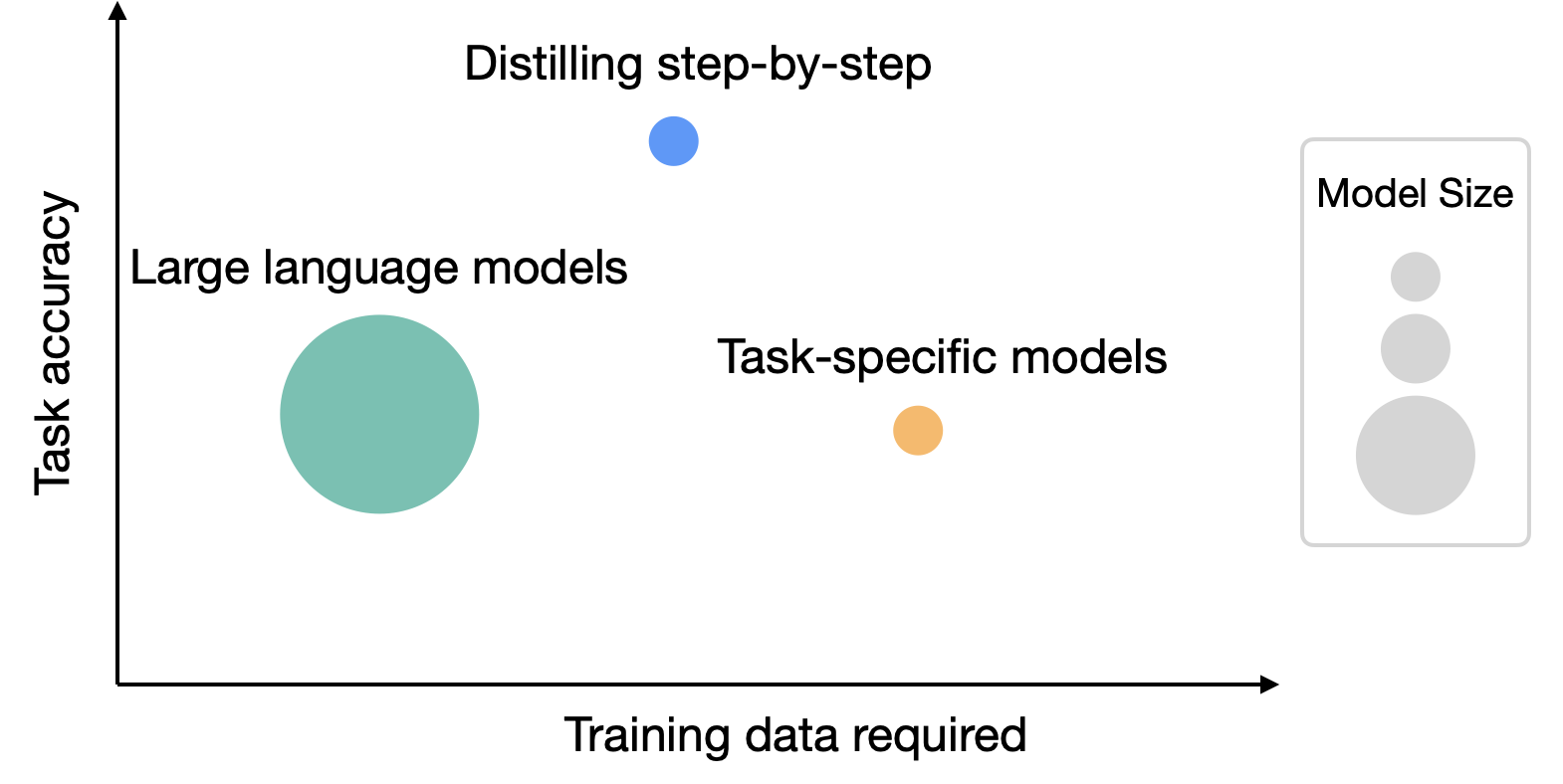 |
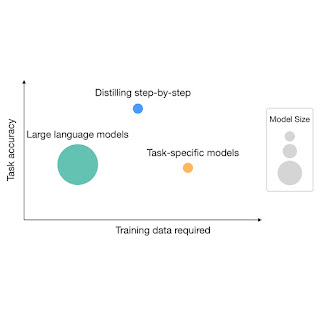
| While LLMs offer strong zero and few-shot performance, they are challenging to serve in practice. On the other hand, traditional ways of training small task-specific models require a large amount of training data. Distilling step-by-step provides a new paradigm that reduces both the deployed model size as well as the number of data required for training. |
Distilling step-by-step
The key idea of distilling step-by-step is to extract informative natural language rationales (i.e., intermediate reasoning steps) from LLMs, which can in turn be used to train small models in a more data-efficient way. Specifically, natural language rationales explain the connections between the input questions and their corresponding outputs. For example, when asked, “Jesse's room is 11 feet long and 15 feet wide. If she already has 16 square feet of carpet, how much more carpet does she need to cover the whole floor?”, an LLM can be prompted by the few-shot chain-of-thought (CoT) prompting technique to provide intermediate rationales, such as, “Area = length * width. Jesse’s room has 11 * 15 square feet.” That better explains the connection from the input to the final answer, “(11 * 15 ) - 16”. These rationales can contain relevant task knowledge, such as “Area = length * width”, that may originally require many data for small models to learn. We utilize these extracted rationales as additional, richer supervision to train small models, in addition to the standard task labels.
 |
| Overview on distilling step-by-step: First, we utilize CoT prompting to extract rationales from an LLM. We then use the generated rationales to train small task-specific models within a multi-task learning framework, where we prepend task prefixes to the input examples and train the model to output differently based on the given task prefix. |
Distilling step-by-step consists of two main stages. In the first stage, we leverage few-shot CoT prompting to extract rationales from LLMs. Specifically, given a task, we prepare few-shot exemplars in the LLM input prompt where each example is composed of a triplet containing: (1) input, (2) rationale, and (3) output. Given the prompt, an LLM is able to mimic the triplet demonstration to generate the rationale for any new input. For instance, in a commonsense question answering task, given the input question “Sammy wanted to go to where the people are. Where might he go? Answer Choices: (a) populated areas, (b) race track, (c) desert, (d) apartment, (e) roadblock”, distilling step-by-step provides the correct answer to the question, “(a) populated areas”, paired with the rationale that provides better connection from the question to the answer, “The answer must be a place with a lot of people. Of the above choices, only populated areas have a lot of people.” By providing CoT examples paired with rationales in the prompt, the in-context learning ability allows LLMs to output corresponding rationales for future unseen inputs.
 |
| We use the few-shot CoT prompting, which contains both an example rationale (highlighted in green) and a label (highlighted in blue), to elicit rationales from an LLM on new input examples. The example is from a commonsense question answering task. |
After the rationales are extracted, in the second stage, we incorporate the rationales in training small models by framing the training process as a multi-task problem. Specifically, we train the small model with a novel rationale generation task in addition to the standard label prediction task. The rationale generation task enables the model to learn to generate the intermediate reasoning steps for the prediction, and guides the model to better predict the resultant label. We prepend task prefixes (i.e., [label] and [rationale] for label prediction and rationale generation, respectively) to the input examples for the model to differentiate the two tasks.
Experimental setup
In the experiments, we consider a 540B PaLM model as the LLM. For task-specific downstream models, we use T5 models. For CoT prompting, we use the original CoT prompts when available and curate our own examples for new datasets. We conduct the experiments on four benchmark datasets across three different NLP tasks: e-SNLI and ANLI for natural language inference; CQA for commonsense question answering; and SVAMP for arithmetic math word problems. We include two sets of baseline methods. For comparison to few-shot prompted LLMs, we compare to few-shot CoT prompting with a 540B PaLM model. In the paper, we also compare standard task-specific model training to both standard fine-tuning and standard distillation. In this blogpost, we will focus on the comparisons to standard fine-tuning for illustration purposes.
Less training data
Compared to standard fine-tuning, the distilling step-by-step method achieves better performance using much less training data. For instance, on the e-SNLI dataset, we achieve better performance than standard fine-tuning when using only 12.5% of the full dataset (shown in the upper left quadrant below). Similarly, we achieve a dataset size reduction of 75%, 25% and 20% on ANLI, CQA, and SVAMP.
 |
| Distilling step-by-step compared to standard fine-tuning using 220M T5 models on varying sizes of human-labeled datasets. On all datasets, distilling step-by-step is able to outperform standard fine-tuning, trained on the full dataset, by using much less training examples. |
Smaller deployed model size
Compared to few-shot CoT prompted LLMs, distilling step-by-step achieves better performance using much smaller model sizes. For instance, on the e-SNLI dataset, we achieve better performance than 540B PaLM by using a 220M T5 model. On ANLI, we achieve better performance than 540B PaLM by using a 770M T5 model, which is over 700X smaller. Note that on ANLI, the same 770M T5 model struggles to match PaLM’s performance using standard fine-tuning.
 |
| We perform distilling step-by-step and standard fine-tuning on varying sizes of T5 models and compare their performance to LLM baselines, i.e., Few-shot CoT and PINTO Tuning. Distilling step-by-step is able to outperform LLM baselines by using much smaller models, e.g., over 700× smaller models on ANLI. Standard fine-tuning fails to match LLM’s performance using the same model size. |
Distilling step-by-step outperforms few-shot LLMs with smaller models using less data
Finally, we explore the smallest model sizes and the least amount of data for distilling step-by-step to outperform PaLM’s few-shot performance. For instance, on ANLI, we surpass the performance of the 540B PaLM using a 770M T5 model. This smaller model only uses 80% of the full dataset. Meanwhile, we observe that standard fine-tuning cannot catch up with PaLM’s performance even using 100% of the full dataset. This suggests that distilling step-by-step simultaneously reduces the model size as well as the amount of data required to outperform LLMs.
 |
| We show the minimum size of T5 models and the least amount of human-labeled examples required for distilling step-by-step to outperform LLM’s few-shot CoT by a coarse-grained search. Distilling step-by-step is able to outperform few-shot CoT using not only much smaller models, but it also achieves so with much less training examples compared to standard fine-tuning. |
Conclusion
We propose distilling step-by-step, a novel mechanism that extracts rationales from LLMs as informative supervision in training small, task-specific models. We show that distilling step-by-step reduces both the training dataset required to curate task-specific smaller models and the model size required to achieve, and even surpass, a few-shot prompted LLM’s performance. Overall, distilling step-by-step presents a resource-efficient paradigm that tackles the trade-off between model size and training data required.
Availability on Google Cloud Platform
Distilling step-by-step is available for private preview on Vertex AI. If you are interested in trying it out, please contact vertex-llm-tuning-preview@google.com with your Google Cloud Project number and a summary of your use case.
Acknowledgements
This research was conducted by Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Thanks to Xiang Zhang and Sergey Ioffe for their valuable feedback.
Quick links
Other posts of interest
-
April 18, 2025
InstructPipe: Generating Visual Blocks pipelines with human instructions and LLMs- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

April 17, 2025
Teaching machines the language of biology: Scaling large language models for next-generation single-cell analysis- Health & Bioscience ·
- Natural Language Processing
-

April 3, 2025
Evaluating progress of LLMs on scientific problem-solving- General Science ·
- Generative AI ·
- Natural Language Processing