Visual captions: Using large language models to augment video conferences with dynamic visuals
June 6, 2023
Posted by Ruofei Du, Research Scientist, and Alex Olwal, Senior Staff Research Scientist, Google Augmented Reality

Recent advances in video conferencing have significantly improved remote video communication through features like live captioning and noise cancellation. However, there are various situations where dynamic visual augmentation would be useful to better convey complex and nuanced information. For example, when discussing what to order at a Japanese restaurant, your friends could share visuals that would help you feel more confident about ordering the “Sukiyaki”. Or when talking about your recent family trip to San Francisco, you may want to show a photo from your personal album.
In “Visual Captions: Augmenting Verbal Communication With On-the-fly Visuals”, presented at ACM CHI 2023, we introduce a system that uses verbal cues to augment synchronous video communication with real-time visuals. We fine-tuned a large language model to proactively suggest relevant visuals in open-vocabulary conversations using a dataset we curated for this purpose. We open sourced Visual Captions as part of the ARChat project, which is designed for rapid prototyping of augmented communication with real-time transcription.
 |
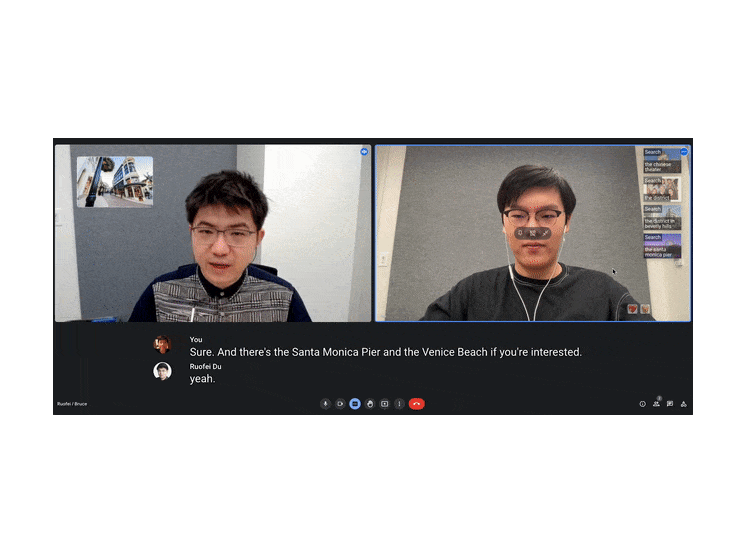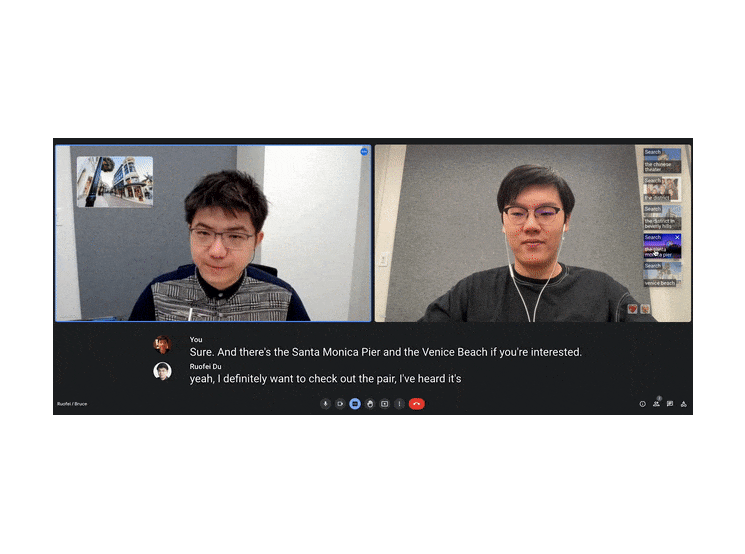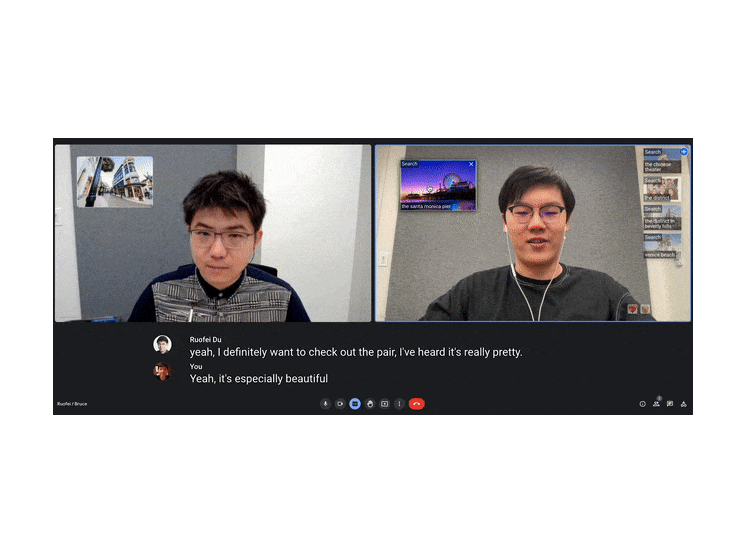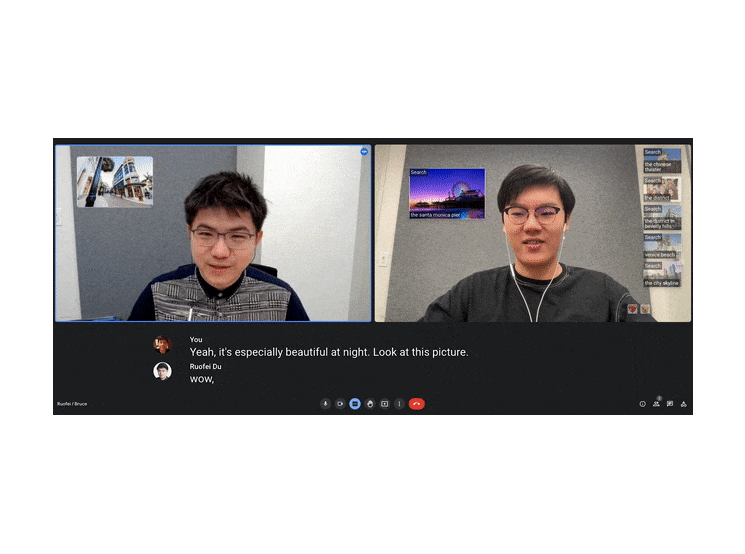
| Visual Captions facilitates verbal communication with real-time visuals. The system is even robust against typical mistakes that may often appear in real-time speech-to-text transcription. For example, out of context, the transcription model misunderstood the word "pier" as "pair", but Visual Captions still recommends images of the Santa Monica Pier. |
Design space for augmenting verbal communication with dynamic visuals
We invited 10 internal participants, each with various technical and non-technical backgrounds, including software engineers, researchers, UX designers, visual artists, students, etc., to discuss their particular needs and desires for a potential real-time visual augmentation service. In two sessions, we introduced low-fidelity prototypes of the envisioned system, followed by video demos of the existing text-to-image systems. These discussions informed a design space with eight dimensions for visual augmentation of real-time conversations, labeled below as D1 to D8.
Visual augmentations could be synchronous or asynchronous with the conversation (D1: Temporal), could be used for both expressing and understanding speech content (D2: Subject), and could be applied using a wide range of different visual content, visual types, and visual sources (D3: Visual). Such visual augmentation might vary depending on the scale of the meetings (D4: Scale) and whether a meeting is in co-located or remote settings (D5: Space). These factors also influence whether the visuals should be displayed privately, shared between participants, or public to everyone (D6: Privacy). Participants also identified different ways in which they would like to interact with the system while having conversations (D7: Initiation). For example, people proposed different levels of “proactivity”, which indicates the degree to which users would like the model to take the initiative. Finally, participants envisioned different methods of interaction, for example, using speech or gestures for input. (D8: Interaction).
 |
| Design space for augmenting verbal communication with dynamic visuals. |
Informed by this initial feedback, we designed Visual Captions to focus on generating synchronous visuals of semantically relevant visual content, type, and source. While participants in these initial exploratory sessions were participating in one-to-one remote conversations, deployment of Visual Captions in the wild will often be in one-to-many (e.g., an individual giving a presentation to an audience) and many-to-many scenarios (e.g., a discussion among multiple people in a meeting).
Because the visual that best complements a conversation depends strongly on the context of the discussion, we needed a training set specific to this purpose. So, we collected a dataset of 1595 quadruples of language (1), visual content (2), type (3), and source (4) across a variety of contexts, including daily conversations, lectures, and travel guides. For example, “I would love to see it!” corresponds to visual content of “face smiling”, a visual type of “emoji”, and visual source of “public search”. “Did she tell you about our trip to Mexico?” corresponds to visual content of “a photo from the trip to Mexico'', a visual type of “photo”, and visual source of “personal album”. We publicly released this VC1.5K dataset for the research community.
Visual intent prediction model
To predict what visuals could supplement a conversation, we trained a visual intent prediction model based on a large language model using the VC1.5K dataset. For training, we parsed each visual intent into the format of "<Visual Type> of <Visual Content> from <Visual Source>".
{"prompt": "<Previous Two Sentences> →",
"completion":
"<Visual Type 1> of "<Visual Type 1> from "<Visual Source 1>;
<Visual Type 2> of "<Visual Type 2> from "<Visual Source 2>;
... \𝑛"}
Using this format, this system can handle open-vocabulary conversations and contextually predict visual content, visual source, and visual type. Anecdotally, we found that it outperforms keyword-based approaches, which fail to handle open-vocabulary examples like “Your aunt Amy will be visiting this Saturday,” and cannot suggest relevant visual types or visual sources.
 |
| Examples of visual intent predictions by our model. |
We used 1276 (80%) examples from the VC1.5K dataset for fine-tuning the large language model and the remaining 319 (20%) examples as test data. We measured the performance of the fine-tuned model with the token accuracy metric, i.e., the percentage of tokens in a batch that were correctly predicted by the model. During training, our model reached a training token accuracy of 97% and a validation token accuracy of 87%.
Performance
To evaluate the utility of the trained Visual Captions model, we invited 89 participants to perform 846 tasks. They were asked to provide feedback on a scale of "1 — Strongly Disagree" to "7 — Strongly Agree" for six qualitative statements. Most participants preferred to have the visual during a conversation (Q1, 83% ≥ 5–Somewhat Agree). Moreover, they considered the displayed visuals to be useful and informative (Q2, 82% ≥ 5–Somewhat Agree), high-quality (Q3, 82% ≥ 5–Somewhat Agree), and relevant to the original speech (Q4, 84% ≥ 5–Somewhat Agree). Participants also found the predicted visual type (Q5, 87% ≥ 5–Somewhat Agree) and visual source (Q6, 86% ≥ 5–Somewhat Agree) to be accurate given the context of the corresponding conversation.
 |
| Technical evaluation results of the visual prediction model rated by study participants. |
With this fine-tuned visual intent prediction model, we developed Visual Captions on the ARChat platform, which can add new interactive widgets directly on the camera streams of video conferencing platforms, such as Google Meet. As shown in the system workflow below, Visual Captions automatically captures the user's speech, retrieves the last sentences, feeds them into the visual intent prediction model every 100 ms, retrieves relevant visuals, and then suggests visuals in real time.
 |
| System workflow of Visual Captions. |
Visual Captions provides three levels of proactivity when suggesting visuals:
- Auto-display (high-proactivity): The system autonomously searches and displays visuals publicly to all meeting participants. No user interaction required.
- Auto-suggest (medium-proactivity): The suggested visuals are shown in a private scrolling view. A user then clicks a visual to display it publicly. In this mode, the system is proactively recommending visuals, but the user decides when and what to display.
- On-demand-suggest (low-proactivity): The system will only suggest visuals if a user presses the spacebar.
Quantitative and qualitative evaluation: User studies
We evaluated Visual Captions in both a controlled lab study (n = 26) and in-the-wild deployment studies (n = 10). Participants found that real-time visuals facilitated live conversations by helping explain unfamiliar concepts, resolve language ambiguities, and make conversations more engaging. Participants also reported different preferences for interacting with the system in-situ, and that varying levels of proactivity were preferred in different social scenarios.
 |
| Participants’ Task Load Index and Likert scale ratings (from 1 - Strongly Disagree to 7 - Strongly Agree) of four conversations without Visual Captions (“No VC”) and the three Visual Captions modes: auto-display, auto-suggest, and on-demand suggest. |
Conclusions and future directions
This work proposes a system for real-time visual augmentation of verbal communication, called Visual Captions, that was trained using a dataset of 1595 visual intents collected from 246 participants, covering 15 topic categories. We publicly release the training dataset, VC1.5K to the research community to support further research in this space. We have also deployed Visual Captions in ARChat, which facilitates video conferences in Google Meet by transcribing meetings and augmenting the camera video streams.
Visual Captions represents a significant step towards enhancing verbal communication with on-the-fly visuals. By understanding the importance of visual cues in everyday conversations, we can create more effective communication tools and improve how people connect.
Acknowledgements
This work is a collaboration across multiple teams at Google. Key contributors to the project include Xingyu “Bruce” Liu, Vladimir Kirilyuk, Xiuxiu Yuan, Peggy Chi, Alex Olwal, and Ruofei Du.
We would like to extend our thanks to those on the ARChat team who provided assistance, including Jason Mayes, Max Spear, Na Li, Jun Zhang, Jing Jin, Yuan Ren, Adarsh Kowdle, Ping Yu, Darcy Philippon, and Ezgi Oztelcan. We would also like to thank the many people with whom we've had insightful discussions and those who provided feedback on the manuscript, including Eric Turner, Yinda Zhang, Feitong Tan, Danhang Tang, and Shahram Izadi. We would also like to thank our CHI reviewers for their insightful feedback.
Other posts of interest
-

April 23, 2024
Safely repairing broken builds with ML- Machine Intelligence ·
- Software Systems & Engineering
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics